-
vim-perl needs your help
The vim-perl projects collects all the Perl-related vim support files in one place, and now it needs more TLC that I can provide it, which probably means someone other than me needs to maintain it.
-
My YAPC::NA 2012 recap
Random notes and comments about YAPC::NA in Madison, WI -
The great and mighty crowdsourced YAPC::NA 2012 recap list
Many people are posting about YAPC::NA 2012. Some of these I've already tweeted at @perlbuzz.- YAPC::NA 2012's legacy for future organizers, by JT Smith (blogs.perl.org)
- Joel Berger (blogs.perl.org)
- How @mithaldu put the YAPC videos on YouTube (blogs.perl.org)
- Sawyer_X (blogs.perl.org)
- Scrottie (livejournal.com)
- Stephen Belcher (blogs.xzion.com)
- Reini Urban (blogs.perl.org)
-
My YAPC::NA 2012 notes and recap
Random notes and comments about YAPC::NA in Madison, WI.ack 2.0
I uploaded ack 2.00alpha01 to the CPAN.
All that week, Rob Hoelz did a ton of work, and Jerry Gay was invaluable in helping us work through some configuration issues. Then, out of nowhere, Ryan Olson swoops in to close some sticky issues in the GitHub queue. I love conferences for bringing people together to get things done.
Finally, on Thursday night at the Bad Movie BOF I hacked away on the final few tickets while watching "Computer Beach Party (1987)". Halfway through MST3K's take on "Catalina Caper (1967)", I made the alpha release. If that's not heaven, I don't know what is.
Mojolicious
Glen Hinkle
Mojolicous looks really cool. Glen called it a "full web framework, not partial," although I'm not sure what would count as a partial framework.
It has no outside dependencies, and works to have a lot of bleeding edge features like websockets, non-blocking events, IPv6 and concurrent requests.
Mojo::UserAgentis the client that is part of Mojolicious, and it's got all sorts of cool features:- DOM parsing
- text selection via CSS selectors
- For example, "give me all the text that is
#introduction ul li." - Command line:
mojo get mojolicio.us '#introduction ul li'
- For example, "give me all the text that is
- JSON parsing
- JSON pointers
- JSON pointers look like XPath as a way of specifying data in a JSON string
Mojolicious is based on "routes", which look like:
get '/' get '/:placeholder' get '/#releaxed' get '/*wildcard'The latter three are (apparently) ways of making flexible URL specifications that then return information to your app about the URL.
Sample app with Mojolicious::Lite:
use Mojolicious::Lite; get '/' => sub { my $self = shift; $self->render( text => 'mytemplate' ); } app->start; __DATA__ @@ mytemplate.html.ep Hello!Mojolicious also has its own templating language that looks a lot like Mason, but Glen said you can use Template Toolkit as well (and presumably others, but TT was the only one I was interested in.)
Full Mojolicious includes a dev server called Morbo and you can run your apps through the Hypnotoad "hot-code-reloading production server" if you don't want to run under Apache/etc.
Another selling point for Mojolicious: They value making things "beautiful" and "fun". Glen specifically said "Join our IRC channel. We will not be mean to you."
Perl-as-a-Service shootout
Mark Allen
This was disappointing because I was hoping for recommendations to use or not use a given vendor's offerings. I was hoping at least for "This vendor does this, and that one does that differently," but all I came away with was "they're pretty much the same."
It's a good sign that, as Mark put it, "getting PSGI-compliant apps into PaaS is generally pain free."
His criteria were as follows:
- Ease of deployment
- Performance (ignored)
- Cost (ignored)
- How "magical" the Perl support is (first class or hacked together)
Why ignore performance and cost? I don't know.
Big data and PDL
There were three sessions back-to-back about PDL, the Perl Data Language. It's in the same space as Mathematica and R. I was disappointed because I was hoping for big data analysis outside of just number crunching. The analysis of galaxy luminosity was pretty and looked very easy to do, but it didn't have any application I was interested in. I bailed after the 2nd talk.
My big takeaway from the talk was that I need to take a statistics class.
Web security 101
Michael Peters gave a good intro talk on security, handwaving the tech details with examples of "This is how bad guys can get your info."
Emphasis on not trusting your client data, but I was surprised and disappointed that he seemed to steer people away from Perl's taint mode. He made vague reference to there being bugs with regexes and taint mode, but I don't know what he's referring to.
Taint mode is one of my favorite things about Perl 5, and there are (last I checked) no plans for implementing it in Perl 6. :-(
One of the examples Michael used for an example of an attack with SQL injection used
sleep()to let the attacker find out information about the database based on timings. I asked him to write that up for bobby-tables.com.On being a polyglot
Miyagawa gave a great overview of how he spends time in Perl, Python and Ruby, and what he learns from each, and what each language learns from the others.
Key point: Ruby is not the enemy. They are neighbors.
Things he likes about Ruby:
- Everything is an object
- More Perlish than Python
- Diversity matters = TIMTOTWTDI
- Meta programming built in and encouraged
- Convention of
!and?in method namesstr.upcase!to upcasestrin placestr.islower?to functions that return values
- Ability to omit
self - Everything is an expression.
- No need to type
:(unlike Python) - Implicit better than explicit
- block, iterators and yield
- No semicolons, 2-space indent.
- (This last one gives me the creeps. 2-space indent!??!)
Naming differences between the three:
- Perl naming: Descriptive, boring, clones become
::Simple - Python naming: Descriptive, confusing, everything is
py*or*py - Ruby naming: Fancy, creative, chaotic (Sinatra, Rails, etc)
- With frameworks, all the languages get creative: Django, nbottle, Catalyst, Dancer, Mojolicious
When you're going to borrow something from another language, don't just borrow it, but copy it wholesale. Example: Perl's WWW::Mechanize getting cloned as Ruby's WWW::Mechanize.
Doing Things Wrong, chromatic
chromatic talked about the value of doing things "wrong" and embracing your constraints. Sometimes you can't do The Perfect Job, and that's OK, and sometimes comes out even better.
Example: chromatic wanted to do some parallel web fetching. He could have dug into
LWP::Parallel, but instead he went with what he knew:waitpid()and shelling tocurl.Screen scraping example:
- Obvious answer: HTML::TokeParser::Simple or Mojo::DOM
- Common: Regexes
- Lovely: Template::Extract
Parsing HTML with regex may be the "wrong" way to do it, but sometimes, it's the best solution.
Perl 6 lists
Patrick Michaud talked about all kinds of awesome stuff you can do with lists and arrays in Perl 6. After a bit I stopped trying to take notes and follow what he was saying and instead just let it wash over me so I could absorb the coolness.
I would really like Perl 6 to be easy enough to install for serious play. I need to get my feet back into the Perl 6 pool and see how I can help.
Tweakers Anonymous
John Anderson (genehack)
Quick overview of cool things that he has in his configs.
- "The F keys are not just to skip tracks in your music player."
- Keep your configs in git. You will screw them up. This will save you.
- Make your editor
chmod +xwhen you create a.plfile since you know you will want to run it.
The coolest thing was this plugin called
flymake. Apparently it runs continuously, submitting your code to a compiler (orperl -c) as you type. As soon as John made a typo on a line and moved to the next line, the error line was highlighted. He then demonstrated doing this withPerl::Critic, which must be dog slow, butflymakelets you adjust the frequency of checks.Exceptional Exceptions
Mark Fowler, now at OmniTI. Great discussion of exceptions in Perl.
Returning false on failure sucks because you have to follow your failures all the way up the call tree. It's tedious and error-prone because all it takes is one link in the chain to not propagate the error and you're out of luck.
Using try/catch from Java.
There are three non-deprecated ways of doing exceptions in Perl.
eval
evalis often confused witheval $stringwhich means to compile code. eval is a statement not a block so requires a semicolon after it. It works but it's a pain.Try::Tiny
- Simple extension to the syntax
- Uses
$_not$@
TryCatch
- Has named exception variables
- Fully functional syntax
- Very fast and featureful
- Large dependency base
TryCatch is a little faster than Try::Tiny, but
evalis much much faster than either of them.TryCatch has much more clever syntax, but looks (to me) to be more dangerous.
Mark recommends that whatever you use, you make exceptions out of
Exception::Classobjects. -
Before you write a patch, write an email
(Originally posted to my non-Perl blog)
I often get surprise patches in my projects from people I’ve never heard from. I’m not talking about things like fixing typos, or fixing a bug in the bug tracker. I’m talking about new features, handed over fully-formed. Unfortunately, it’s sometimes the case that the patch doesn’t fit the project, or where the project is going. I feel bad turning down these changes, but it’s what I have to do.
Sometimes it feels like they’re trying to do their best to make the patch a surprise, sort of like working hard to buy your mom an awesome birthday present without her knowing about it. But in the case of contributing to a project, surprise isn’t a good thing. Talking to the project first doesn’t take away from the value of what you’re trying to do. This talking up front may even turn up a better way to do what you want.
There’s nothing wrong with collaborating with others to plan work to be done. In our day-to-day jobs, when management, clients and users push us to start construction of a project before requirements are complete, it’s called WISCY, or Why Isn’t Someone Coding Yet? As programmers, it’s our job to push back against this tendency to avoid wasted work. Sometimes this means pushing back against users, and sometimes it means pushing back against ourselves.
I’m not suggesting that would-be contributors go through some sort of annoying process, filling out online forms to justify their wants. I’m just talking about a simple email. I know that we want to get to the fun part of coding, but it makes sense to spend a few minutes to drop a quick note: “Hey, I love project Foo, and I was thinking about adding a switch to do X.” You’re sure to get back a “Sounds great! Love to have it!” or a “No, thanks, we’ve thought about that and decided not to do that”. Maybe you’ll find that what you’re suggesting is already done and ready for the next release. Or maybe you’ll get no reply to your email at all, which tells you your work will probably be ignored anyway.
I’m not suggesting that you shouldn’t modify code for your own purposes. That’s part of the beauty of using open source. If you need to add a feature for yourself, go ahead. But if your goal is to contribute to the project as well as scratching your own itch, it only makes sense to start with communication.
Communication starts with understanding how the project works. The docs probably include something about the development process the project uses. While you’re at it, join the project’s mailing list and read the last few dozen messages in the archive. I can’t tell you how many times I’ve answered a question or patch from someone when I’ve said the same thing to someone else a week earlier.
Next time you have an idea to contribute a change to an open source project, let someone know what you’re thinking first. Find out if your patch is something the project wants. Find out what the preferred process for submitting changes is. Save yourself from wasted time.
We want your collaboration! We want you your help! Just talk to us first.
-
Test::WWW::Mechanize adds scraping functions
The new 1.40 release of Test::WWW::Mechanize adds functions to help scrape text from your HTML as you test it. This should make things much easier for your integration test of your web apps.
For example, if you want to make sure that this shows up:
<h1>My awesome page!</h1>then you can add an id attribute to the <h1>
<h1 id="pagetitle">My awesome page!</h1>and your test can check for it:
$mech->scraped_id_is( 'pagetitle', 'My Awesome Page!' );Two other functions are added to help in your text extraction: ->scrape_text_by_id() and ->scrape_text_by_attr().
Will these functions help your testing? Do you have other methods that you use to aid testing? As always, I welcome your feedback.
-
Using WWW::Mechanize to get my scratchy 45s
I'm a big fan of WFMU's Beware of the Blog. So much music geekery and arcana in one handy source!
Sometimes there will be a post with lots of MP3s for download, like this one today with long-forgotten 45s of songs paying tribute to Merle Haggard. I don't want to listen to the mp3s in my browser, and I don't want to manually do the Save As dance in the browser.
Perl and WWW::Mechanize to the rescue! If you have WWW::Mechanize installed, you also have the mech-dump utility. mech-dump started as a tool to make it easier to create WWW::Mechanize programs by showing what form fields exist, but it does more than that. By default, mech-dump will fetch a page and display the forms and fields on the web page. If you call it with --links, you'll only get back the links, like so:
alester:~ $ mech-dump --links http://blog.wfmu.org/freeform/2012/04/a-tribute-to-the-hag-mp3s.html http://blog.wfmu.org/freeform/styles.css?v=6 http://static.typepad.com/.shared:v20120403.02-0-g1ba1fe9:typepad:en_us/themes/common/print.css http://blog.wfmu.org/freeform/2012/04/you-cant-put-your-arm-around-a-memory.html?no_prefetch=1 ... etc ...
Filter that output through grep and pass it to xargs and wget, and you've got a handy MP3-only downloader.
alester:~ $ mech-dump --links [big URL] | grep mp3$ | xargs wget --2012-04-04 09:27:32-- http://blogfiles.wfmu.org/GG/Skeeter_Harmon_-_A_Tribute_To_The_Hag.mp3 100%[=======================================================>] 4,935,323 4.08M/s in 1.2s ... etc ...
I suspect very few Mech users are aware of mech-dump, and how handy it can be from the command line. I wish I'd done a better job of publicizing it.
-
Parrot tickets now converted to GitHub
The Parrot project is now using GitHub's issue tracking system. Parrot has used GitHub's source code control for months now, but we had hundreds of tickets in the Trac system. Now, over the past few weeks, I've been working with Rick from GitHub to migrate the tickets out of Trac into GitHub's issue system.
Like most data conversion projects, the challenges were less about the coding and more about making the decisions about how to massage the data between two similar systems. For example, Trac has fields for Severity and Priority of tickets, but GitHub only has free-form tagging, so I had to create GitHub tags that correspond to Severity and Priority in Trac. GitHub's tracking system doesn't handle file attachments, so my conversion code had to make inline comments of the file attachments.
Most time-consuming of all was the conversion of users from Trac to GitHub. We needed the issue history to have accurate user IDs on them, so I needed a big lookup table to do the job. While users like "coke" and "chromatic" have the same user IDs on both the Trac instance and GitHub, Trac user "jonathan" is "jnthn" on GitHub, and so on. Anyone I couldn't find a match for became generic user "Parrot".
The actual code to do all this is only about 200 lines of Perl code, which should be no surprise for someone who has the CPAN at his disposal. I used Net::Trac to read from the Trac instance, and the JSON module to write out JSON files in the GitHub API format. The bulk of the code is project-specific conversions to make little data tweaks like change severity to tags, and to make the output code a little more friendly in Markdown.
I have to specifically thank Rick at GitHub for helping us through this project. I used a lot of his time with questions about how GitHub would handle my import format, and we had two test imports for us to see real results, so that I could adjust my conversion process. The final results are beautiful, and the Parrot team is excited to see this move made.
I've long been a fan of GitHub and how they help out the community, and this just adds to it. This sort of aid to open source projects should stand as an example to other companies that work with open source. Many companies give back to the communities of the projects on which their businesses are based. It's fantastic to have a company willing to use human capital actually working with a project in which they have no direct involvement. In helping us, GitHub gains nothing but the grateful thanks of the Parrot project.
-
Perl::Critic finds annoying little bugs in your code.
My work colleague Mike O'Regan created a policy for the latest version of Perl::Critic.
Now if you have a line of code like this:
my $n += somefunc(); # Should be my $n = somefunc();Perl::Critic will tell you
Augmented assignment operator '+=' used in declaration at line X, column Y. Use simple assignment when initializing variables.If you haven't let Perl::Critic loose on your code yet, now's a great time to try.
To the loyal Perl::Critic users, what's the nastiest bug Perl::Critic found for you? Let me know in the comments.
-
Finding a lost dog's owner with Perl and WWW::Mechanize
It's not every day you get to save a dog with Perl, but Perlbuzz reader Adam Gotch did just that the other day.
Adam tells me "I'm a telecommute Perl/Python contract programmer at O'Reilly Media. I live in Springboro, OH. I've been coding in Perl for about 10 years and love it."
On Saturday, Adam found a dog wandering the highway about a mile from his home. The local shelters didn't open until Monday, so he took it upon himself to try to find the owner himself.
Adam explains:
I located the Warren County dog registration website and discovered a simple web form that allowed you to look up an owner if you had the dog license # and registration year. Not having a clue what a license # looked like, I entered '1' with year '2011' and got a result. Dog license #'s were simple integers. Using binary search, I quickly discovered that there were 24996 registration records for 2011. The web form's search result provided a dog's owner's name, address and phone as well as the dog's breed, color and sex. With this knowledge I decided it was feasible to write a script to pull back all the records and filter for a female brown lab.
The dog registration website was ASP.NET with
__VIEWSTATEand__EVENTVALIDATIONpost variables so a simple LWP script was going to be a pain. I had worked with WWW::Mechanize before so I checked the CPAN docs to see if it was going to work. It seemed to have everything I needed so I began coding. I wrote a quick test to see if I could pull back one record, but no luck. I ran wireshark captures of both a manual post in Chrome and my test script. Comparison of the captures revealed that the submit button name/value was not being sent by my script. Looking at the WWW::Mechanize docs, I found thebuttonparameter to thesubmit_form()method for simulating a submit button click. It worked. I finished the script, looping over all 24996 records and soon I was pulling down all the Warren County dog registration records for 2011.Here's the program Adam wrote:
use WWW::Mechanize; use HTML::TreeBuilder::XPath; use strict; my $m = WWW::Mechanize->new(); $m->get('http://www.co.warren.oh.us/auditor/licensing/dog_search/'); my @info = (); $| = 1; for (my $i = 1; $i < 24997; $i++) { my $response; eval { $response = $m->submit_form( form_number => 1, fields => { 'ctl00$ContentPlaceHolder1$txtlicense' => "$i", 'ctl00$ContentPlaceHolder1$txtyear' => '2011' }, button => 'ctl00$ContentPlaceHolder1$btnSubmit'); }; if (!$@ && $response->is_success) { my $tree = HTML::TreeBuilder::XPath->new; $tree->parse($response->decoded_content); # Use XPath selectors to find fields in the table my $owner_info = $tree->findvalue('//div/fieldset[1]/p'); my $dog_info = $tree->findvalue('//div/fieldset[2]/p'); push @info, [$owner_info, $dog_info, $i]; print "$owner_info|$dog_info|$in"; } else { warn "WARNING: POST FAILED"; } $m->back(); }After that, it was some simple calls to
grepto filter the results:cat warren_county_dogs.txt | grep -i springboro | grep -i lab | grep -i brown | grep -i female > brown_labs.txtThis narrowed down the 25,000 records to 39. That made it easily to visually scan the list and find the addresses that were closest to where the dog was found. That narrowed it down to three. Adam Googled the phone numbers, found that one was a cell, and texted it.
I texted the first number, explaining I had found this dog on the highway and sure enough, it was the owner! He promptly drove to my house to pick up "Izzy". When he arrived he was very glad to have his dog back but also confused as to how I found his phone number. I told him I "scraped" the dog registration site and left it at that (yeah it's a bit unnerving how easy it is to find information on people).
Note that if Adam was using a system that didn't have grep or ack, he could have done the string matching in the Perl program before writing out to the file:
next unless $owner_info =~ /springboro/i; next unless $dog_info =~ /lab/ && $dog_info =~ /brown/ && $dog_info =~ /female/ && $dog_info =~ /lab/;He could probably have done the matching with XPath as well, but I am very green on XPath. Such a modification is left as an exercise to the reader.
Thanks for the story, Adam!
-
Mark Jason Dominus on giving fish
By Mark Jason Dominus, from a talk in 2003, reprinted here with permission. Sadly, it's still relevant today.
The
#perlIRC channel has a big problem. People come in asking questions, say, "How do I remove the first character from a string?" And the answer they get from the regulars on the channel is something like "perldoc perlre".This isn't particularly helpful, since
perlreis a very large reference manual, and even I have trouble reading it. It's sort of like telling someone to read the Camel book when what they want to know is how to get the integer part of a number. Sure, the answer is in there somewhere, but it might take you a year to find it.The channel regulars have this idiotic saying about how if you give a man a fish he can eat for one day, but if you teach him to fish, he can eat for his whole life. Apparently "perldoc perlre" is what passes for "teaching a man to fish" in this channel.
I'm more likely to just answer the question (you use
$string =~ s/.//s) and someone once asked me why. I had to think about that a while. Two easy reasons are that it's helpful and kind, and if you're not in the channel to be helpful and kind, then what's the point of answering questions at all? It's also easy to give the answer, so why not? I've seen people write long treatises on why the querent should be looking in the manual instead of asking on-channel, which it would have been a lot shorter to just answer the question. That's a puzzle all right.The channel regulars say that answering people's questions will make them dependent on you for assistance, which I think is bullshit. Apparently they're worried that the same people will come back and ask more and more and more questions. They seem to have forgotten that if that did happen (and I don't think it does) they could stop answering; problem solved.
The channel regulars also have this fantasy that saying
perldoc perlreis somehow more helpful than simply answering the question, which I also think is bullshit. Something they apparently haven't figured out is that if you really want someone to look in the manual, sayingperldoc perlreis not the way to do it. A much more effective way to get them to look in the manual is to answer the question first, and then, after they thank you, say "You could have found the answer to that in the such-and-so section of the manual." People are a lot more willing to take your advice once you have established that you are a helpful person. Sayingperldoc perlreseems to me to be most effective as a way to get people to decide that Perl programmers are assholes and to quit Perl for some other language.After I wrote the slides for this talk I found an old Usenet discussion in which I expressed many of the same views. One of the Usenet regulars went so far as to say that he didn't answer people's questions because he didn't want to insult their intelligence by suggesting that they would be unable to look in the documentation, and that if he came into a newsgroup with a question and received a straightforward answer to it, he would be offended. I told him that I thought if he really believed that he needed a vacation, because it was totally warped.
Mark Jason Dominus has been doing Perl forever. He is the author of Higher Order Perl which belongs on the shelf of every Perl programmer. Follow him on Twitter at @mjdominus.
-
Spreadsheet::WriteExcel is dead. Long live Excel::Writer::XLSX.
The following is by John McNamara. If you do anything with getting data to users that winds up in Excel, you owe it to yourself to look at John's module.
Last week I released a new version of Excel::Writer::XLSX to CPAN that was 100% API compatible with Spreadsheet::WriteExcel. This marked a milestone as I am now able to move past WriteExcel's feature set and move on to new features that I wasn't able to support previously.
This was achieved with 30 CPAN releases in almost exactly a year. By comparison, WriteExcel took almost 10 years. This gives a fair indication of the disparity of effort required to implement a feature in the pre-Excel 2007 binary xls format as opposed to the new XML based xlsx format.
So, from now on, all new features will go into Excel::Writer::XLSX and Spreadsheet::WriteExcel will be in maintenance mode only.
The first of the new features, conditional formatting, was added yesterday. For a long time has been the most frequently requested feature for WriteExcel but it was always too big a feature to implement in the available time that I had.
With Excel::Writer::XLSX you can now add a format like the following:
$worksheet1->conditional_formatting( 'B3:K12', { type => 'cell', format => $light_red, criteria => '>=', value => 50, } );This will result in output like the following, full example here:
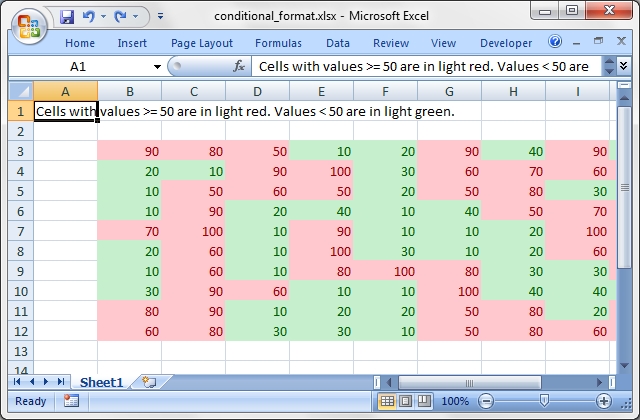
Excel::Writer::XLSX has also been designed differently from Spreadsheet::WriteExcel to allow it to implement some features that previously weren't possible (or at least easy). One of these is the separation of the data and the formatting.
It was a common assumption with new users of WriteExcel that you could write data to a spreadsheet and then apply the formatting afterwards. However, for design reasons related to performance and Excel's file format this wasn't easily implemented. With Excel::Writer::XLSX the back-end architecture is different and this type of feature is not only possible but will be added soon.
If you are a user of Spreadsheet::WriteExcel then now is probably a good time to try out Excel::Writer::XLSX so you can get the new features when them come on-line.
John McNamara is a software engineer living in Ireland. Once a month he drinks a pint of Guinness with Tim Bunce to discuss Perl and open source. He spends a lot of time looking at hexdumps so that you don't have to.
-
There's only one useful way to handle your detractors
This is a repost from my main blog, but it applies to all of us working on Parrot and Perl 6. Keep on keeping on, ignore the trolls, and keep moving forward to completing the vision. Here's a Reddit/Slashdot/whatever thread that never happened:Internet crank on Reddit: "Hey, Steve Jobs, I guess that new iPad looks cool, but I think iPad is a stupid name, it makes me think of sanitary napkins."
Can you even imagine Steve Jobs in this sort of time-wasting and emotionally draining tit-for-tat in a thread on Slashdot? On reddit? In some blog's comment section? Of course not. Justification of his plans would take away from the amazing things that he needed to achieve. Naysayers are part of every project. How many people do you think pissed on Jimmy Wales' little project to aggregate knowledge? Nobody's going to spend their time writing encyclopedia entries! And yet there it is. On a personal level, if I listened to everyone who thought I was wasting my time improving on find + grep you'd never have ack. We all have to persevere in the face of adversity to ideas, but there's more than that. We need to ignore our detractors. Despite how silly and time-wasting it is to argue your motivations and reasons for undertaking a project, many of us feel compelled to argue with everyone who disagrees with us. I suggest you not waste your time. On the Internet, the attitude is "Why wasn't I consulted?" Every anti-social child (measured by calendar or maturity) with a keyboard thinks it's his responsibility to piss on everything he doesn't like. They'll be there always. You can no more make them go away than you would by arguing with the rain. What are you hoping to achieve by arguing with someone who doesn't like your project? Do you expect that he'll come around to your way of thinking? It won't happen through words. Not only does arguing with your critics waste your precious time, but it tells them, and every other crank reading, that you're willing to engage in debate about what you're doing. Don't encourage them! Let them find a more receptive target. I'm not saying that factual misstatements need to be ignored. If something is provably incorrect, go ahead and counter it with facts. However, most of the time these message thread pissing wars get down to "I would not be doing what you are doing, and therefore you are wrong for doing so." The only thing that has a chance of silencing your critics is success at what you do. Arguing with the naysayers doesn't get you any closer to that.Steve: "Yeah, well, here's why we called it that. (Long explanation justifying his choices)"
Crank #2: "Well, why didn't you call it the iTablet? I think that would have been a good name. What does everyone else think?"
Crank #3: "What does it have to be iAnything? I'm tired of the i- prefix."
Steve: "We thought about that, but ... (More explanation about his choices)"
Crank #1: "And really, isn't it just a bigger iPod Touch? I would never carry that around with me. And come on, you're just trying to redo the Newton anyway LOL"
Steve: "My logic behind the iPad is (vision, business plan, blah blah blah)"
-
Notes from Damian Conway's sessions at OSCON 2011
Here are my notes on two sessions from Damian Conway: The Conway Channel, and (Re)Developing in Perl 6. My notes are scattershot because it's awfully hard to watch and listen and take notes in a Damian. I wish he'd post his slides, but I understand why he doesn't/can't.
(These notes are extracted from my notes from OSCON 2011. Other topics include API design, PostgreSQL, Jenkins and Cornac.
The Conway Channel
The Conway Channel is Damian Conway's annual discussion of new tools that he's created in the past year.
Regexp::Grammars is all sorts of parsing stuff for Perl 5.10 regexes, and it went entirely over my head.
IO::Prompter is an updated version of IO::Prompt which is pretty cool already. It only works Perl with 5.10+. IO::Prompt makes it easy to prompt the user for input, and the new IO::Prompter adds more options and data validation.
# Get a number my $n = prompt -num 'Enter a number'; # Get a password with asterisks my $passwd = prompt 'Enter your password', -echo=>'*'; # Menu with nested options my $selection = prompt 'Choose wisely...', -menu => { wealth => [ 'moderate', 'vast', 'incalculable' ], health => [ 'hale', 'hearty', 'rude' ], wisdom => [ 'cosmic', 'folk' ], }, '>';Data::Show is like Data::Dumper but also shows helpful debug tips like variable names and origin of the statement. It doesn't try to serialize your output like Data::Dumper does, which is a good thing. Data::Show is now my default data debug tool.
my $person = { name => 'Quinn', preferred_games => { wii => 'Mario Party 8', board => 'Life: Spongebob Squarepants Edition', }, aliases => [ 'Shmoo', 'Monkeybutt' ], greeter => sub { my $name = shift; say "Hello $name" }, }; show $person; ======( $person )====================[ 'data-show.pl', line 20 ]====== { aliases => ["Shmoo", "Monkeybutt"], greeter => sub { ... }, name => "Quinn", preferred_games => { board => "Life: Spongebob Squarepants Edition", wii => "Mario Party 8", }, }Acme::Crap is a joke module that adds a crap function that also lets you use exclamation points to show severity of the error.use Acme::Crap; crap 'This broke'; crap! 'This other thing broke'; crap!! 'A third thing broke'; crap!!! 'A four thing broke'; This broke at acme-crap.pl line 10 This other thing broke! at acme-crap.pl line 11 A Third Thing Broke!! at acme-crap.pl line 12 A FOUR THING BROKE!!! at acme-crap.pl line 13
As with most of Damian's joke modules, you're not likely to use this in a real program, but to learn from how it works internally. In Acme::Crap's case, the lesson is in overloading the ! operator.
(Re)Developing Perl 5 Modules in Perl 6
Perl isn't a programming language. It's a life support system for CPAN.
Damian ported some of his Perl 5 modules to Perl 6 as a learning exercise.
Acme::Don't
Makes a block of code not get executed, so it gets syntax checked but not run.
# Usage example use Acme::Don't; don't { blah(); blah(); blah();Perl 6 implementation
module Acme::Don't; use v6; sub don't (&) is export {}Lessons:
- No homonyms in Perl 6
- No cargo-cult vestigials
- Fewer implicit behaviours
- A little more typing required
- Still obviously Perlish
IO::Insitu
Modifies files in place.
- Parameter lists really help
- Smarter open() helps too
- Roles let you mix in behviours
- A lot less typing required
- Mainly because of better builtins
Smart::Comments
- Perl 6's macros kick source filters' butt
- Mutate grammar, not source
- Still room for cleverness
- No Perl 6 implementation yet has full macro support
- No Perl 6 implementation yet has STD grammar
Perl 6 is solid enough now. Start thinking about porting modules.
-
ack 1.96 released, now ignores minified Javascript files
I released ack 1.96 last night. ack is a code searching tool like grep that is tuned for programmers with large trees of heterogeneous source code. Details about ack are at betterthangrep.com. You can install App::Ack from the CPAN, or follow other instructions at betterthangrep.com. Details of the update: * Now ignores minified Javascript files. Anything matching -min.js or .min.js is ignored. * Lua can now get detected from the shebang line. Thanks, Matthew Wild. * Added support for version numbers in executables in shebang detection. Now if your Perl program's shebang refers to /usr/local/bin/perl-5.14.1, ack will find it. * Added Groovy support (--groovy). * Added .pm6 as a --perl extension. -
Nurturing new open source contributors
In a recent non-public thread on Google Plus about what someone saw as too much low-quality code on CPAN, Brian Cassidy gave some great thoughts (quoted with his permission) about how to handle contributions from newcomers:
New authors should not be "beaten" for not following standard practices, rather coached and mentored into becoming productive members of our culture. Disciplining new authors is counter not only to our culture, but it goes against the release early/release often mantra we often hear in the open source ecosystem.
It's very easy to dismiss someone as ignorant and cast them aside (in retrospect, I'm ashamed to say I've done it too). The hard road is to offer them a hand, show them the ropes.
Not everybody has time for that, and we'll never save people from themselves (no matter how hard we try). But before you rush to dismiss someone's effort (that they've submitted for public scrutiny, no less) think about how you would've like to have been treated when you were new.
A kind word of encouragement can go a long way.
Do you have tales to tell of how you helped guide a newcomer, whether in Perl or elsewhere? Please post your stories.
-
The future of Perl 5
Jesse Vincent, the pumpking for Perl 5, gave a talk at OSCON called "Perl 5.16 and beyond" where he lays out the future of Perl 5. The slides are up on slideshare, and they're well worth reading. I haven't read perl5-porters, the Perl 5 maintainers' mailing list, in a few years, and Jesse's slides are an eye-opener to the trials and tribulations of keeping Perl 5 usable in legacy situations but moving forward with new innovations.
The pumpking is sort of the project leader for Perl 5, and arbiter of what gets committed into the source tree. The pumpking also used to be the person who created the releases, but as Jesse points out below, this responsibility has been delegated to others. The term "pumpking" comes from the holder of the patch pumpkin.
Key points from the slides:
- Perl 5 is now on a regular release schedule, where releases are made based on the calendar, not some critical mass of changes.
- The dual track of odd numbers (5.13.x) for development releases and even numbers (5.14.x) for production releases continues.
- Although Perl 5.14.1 is current production, 5.12.4 and 5.15.0 have recently been released as well.
- Releases used to take three weeks for a single pumpking to do. Now it's a documented process that takes only a few hours. Releases are done by rotating volunteer release engineers. Per Larry, the time of hero pumpkings is over.
- As Perl 5 changes much more quickly, we need to be able to recover from mistakes. Perl should have sane defaults. Perl 5 should run everywhere: Every OS, every browser, every phone.
- Forward changes should not break older code. Programmers shouldn't have to build defensive code to protect against future changes to Perl 5.
- The Perl runtime needs to slim down. Old modules are getting yanked from core and moved to CPAN. Not deprecating, but decoupling. We need to release a version of the Perl core that contains all the stuff we've yanked out of the "slim" core distribution.
- The test suite needs to be split into three types of tests: language, bug-fix and implementation.
- Jesse wants saner defaults in the future, to make Perl 5 cleaner, simpler and easier to work with:
- warnings on
- autodie-esque behavior
- throwing exceptions rather than returning on failure
- 1-arg and 2-arg open gone
- Latin-1 autopromote off
- utf-8 autopromote on
- Basic classes and methods
- No indirect object syntax
- How to make this happen faster? Donate to the Perl 5 Core Maintenance Fund.
I couldn't attend Jesse's talk because I was speaking about community and project management with Github in the same time slot, so if video exists I'd love to see it. And thanks very much to Jesse and the rest of p5p for keeping Perl 5 so amazing.
-
YAPC::NA 2012 gets away from RTFM marketing
Too many times I've seen a conference announced once, and then never heard about it again. It's what I call the RTFM method of marketing: Either you happen to know about the event, or you lose out. This year for YAPC::NA, the annual North American grassroots Perl conference, lead organizer JT Smith isn't going to let that happen.
No sooner had the 2011 conference wrapped up when JT started daily postings about 2012's event to the YAPC::NA blog. He plans to keep that pace going for the next year, until June 13th, 2012 when 2012's event start. The goal is to keep people thinking about YAPC::NA in the next eleven months, and to keep everyone's expectations high. "Everyone at YAPC 2011 laughed at me when I said I was going to do a blog post a day," JT told me on Sunday, "but I've got the next 300 postings planned out."
It's not just frequency that's different this time. JT's writing about the details of the conference, and why you'd want to attend. His posts give tips about the best way to travel to Madison, and attract potential attendees with views of the conference location on the lake. A "spouse program" for the non-hacker members of the family is also high on his publicity list.
As JT and I ate lunch at the bar where he hopes to have a YAPC beer night, we discussed the mechanics of this ongoing communication campaign. JT has the next thirty postings written and posted to Tumblr with future publication dates, letting him create postings in batches, rather than every day. "I chose Tumblr for the blog because it has the best posting scheduling system," he told me.
You can follow the YAPC::NA Twitter stream at @yapcna, or the blog itself at blog.yapcna.org.
I give "RTFM marketing" that name because it's an extension of the geek notion of RTFM. "RTFM" comes from the rude geek response of "RTFM", or "Read the F-ing Manual". It's used as a reply to a question that the geek thinks should not have been asked, because the information exists somewhere that the querent could have looked himself. It's as if the rude geek is saying "The information exists in at least one place that I know of, and therefore you should know that information, too."
The idea that one should just have known about a given piece of information applies to this sort of undermarketing as well. Project leaders seem to think that when information has been published once, everyone will know about it. The RTFM marketers expect that everyone know what they do, read the blogs they do, travel in the same online circles as they do. This is a recipe for failure.
This mindset can be crippling when it comes to publicizing projects and events. Organizers do their projects a disservice when they market their endeavors with the expectation that everyone will automatically know about something simply because they're written one blog post about it.
RTFM marketers also don't spread their messages wide enough. They advertise to the echo chamber of the circles in which they normally run. They'll post to the standard blogs, post to the mailing lists they read, or discuss it in the IRC channels they frequent. This limits the potential audience for the project to the one with which the project leader is already familiar.
Tips for doing open source project marketing right:
- Write & post frequently.
- Write & post in many disparate locations.
- Explain the benefits. Explicitly tell the reader why they would want to attend your event or use your software.
- Change your messages. Don't post the same thing twice.
- Never assume that someone will have read your previous message. It's OK to repeat something stated in a previous message.
- You don't know your potential audience as well as you think you do. Think big.
I'd love to hear stories and ideas about how you got the word out about your project.
-
Perl 5.14 is now available
A new version of Perl, 5.14, was officially released on 14th May following the successful test period, including the testing of release candidates. This is the first release of Perl 5 using the new annual schedule.
There are a number of enhancements and alterations in this version, a full list of changes can be found at (http://perl5.git.perl.org/perl.git/blob/HEAD:/pod/perldelta.pod), a summary of some of the changes:
- Unicode 6.0 support, along with many, many improvements to our Unicode-related features
- Improved support for IPv6
- Significantly easier autoconfiguration of the CPAN client
- A new /r flag which makes s/// substitutions non-destructive
- New regular expression flags to control whether matched strings should be treated as ASCII or Unicode
- New "package Foo { }" syntax
- Uses less memory and CPU than previous releases
- A swathe of bug fixes, a large number associated with the work of Dave Mitchell (http://news.perlfoundation.org/2011/05/fixing-perl5-core-bugs-report-11.html) who has been fixing some deep bugs thanks to a TPF grant;
It is important to note that this version marks the official end of support for Perl 5.10.
This work is just one year of development since the release of Perl 5.12.0. It contains nearly 550,000 lines of changes from close to 3,000 files, this work was done by 150 authors and committers. The documentation, as always, pays tribute to those people who worked hard on this new version, "Many of the changes included in this version originated in the CPAN modules included in Perl's core. We're grateful to the entire CPAN community for helping Perl to flourish." The success of this version is dependent on the great work of the whole community, a particular note of thanks should go to Jesse Vincent for his coordination skills as release manager for 5.14.
-
Stand up for your communities and projects
In the flurry of commentary about Sunday's blog post, three themes have recurred:
- Andy has done bad things, too!
- You didn't give specifics!
- Welcome to the Internet, that's just how people are.
Yes, I've done anti-social things before. I've been part of the problem. That fact doesn't change the validity of my points. We still need strong, human-based communities as the bedrock of any open source project, and those communities can only thrive when people are respected.
Second, I intentionally did not list specific grievances. I don't need to. It's not necessary to give an example of blatant disrespect for us to recognize it. I don't have to mention a time when someone disregarded the basic humanity of others. We've all seen it.
Third, I understand that anti-social behavior passes for normal on the Net, in open source, and among programmers. That doesn't mean we have to let it go unchallenged, or believe that nothing can be done. I accept that this is often the normal state, but I do not approve of it. We can be better than that.
Today's post from the always-insightful Seth Godin couldn't be more timely.
A bully acts up in a meeting or in an online forum. He gets called on it and chastised for his behavior.
The bully then calls out the person who cited their behavior in the first place. He twists their words, casts blame and becomes an aggrieved victim.
Often, members of the tribe then respond by backing off, by making amends, by giving the bully another chance.
And soon the cycle continues.
Brands do this, bosses do it and so do passers-by. Being a bully is a choice, and falling for this cycle, permitting it to continue, is a mistake.
This fits with something chromatic told me last night. He said, "I want people to know that they have permission to stand up to bad behavior." So here it is.
Every one of us has the permission to stand up to the bullies, to the anti-social behavior in our communities. In fact, we not only have permission; we have the responsibility.
Next time someone, for example, cusses out a newbie for asking a "stupid" question, let the offender know how much he or she is hurting the community. Don't accept the bully's excuses for being cruel and abusive to others. If moderators or persons of authority can't or won't intervene, don't be afraid to walk away.
Bullies are damage and need to be routed around. Start your own community if need be, and make sure the people from the original community know about it. Vote with your feet.
It's time to stop pretending this problem doesn't exist. It's time to stop accepting that it's just the way things are. It's time to stand up for your communities.